ML Algorithm Explained: Decision Tree
- By AIPI3 Machine Learning Team

Decision Tree is a supervised machine learning algorithm, which utilizes a tree structure to predict values of given data points. It can be used for both classification and regression tasks. Decision Tree has many applications such as fraud detection, marketing optimization, customer segmentation, and much more.
Advantages:
- It is easy to implement and interpret compared to other algorithms.
- It can handle different types of variables (continuous, discrete, etc.).
Disadvantages:
- It can require significant processing capability for training.
- It is prone to overfitting and a change to a single variable can affect the algorithm.
In this blog post, we provide an overview of the Decision
Tree algorithm with an example of algorithm implementation with code.
Basic Concepts
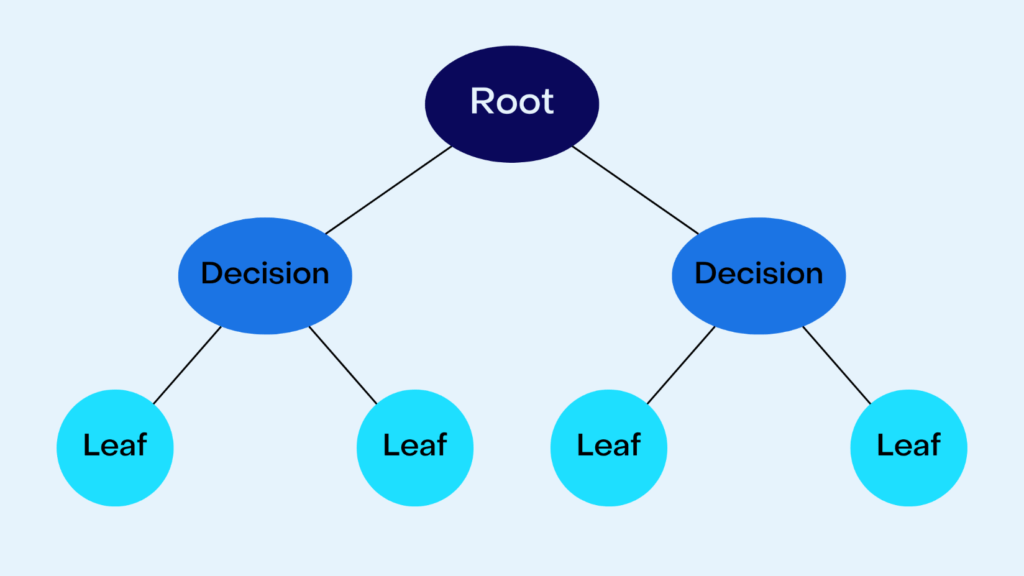
Nodes
A decision tree consists of a series of nodes. The root node represents the initial data set. Each node is split into two or more nodes based on features within the data, and the resulting nodes are called decision nodes. The process is continued until each node can no longer be split. The non-splittable node is referred to as a leaf node or a terminal node, and it is here where the predicted values are output.
Information Gain
When a node is split, the entropy of the dataset changes. The entropy associated with a variable represents the uncertainty related to possible outcomes from that variable. Therefore, we are interested in minimizing this uncertainty. Information gain is the change in entropy before and after a split. The following formula can be used to calculate entropy information gain.
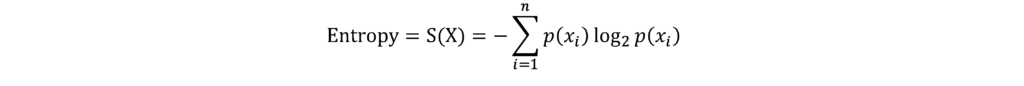
Where:
- i represents the number of classes in the data set.
- p(xi) represents the probability of data belonging to class i.
Gini Index
The Gini Index is a type of cost function used to evaluate a split based on the sum of squared probabilities of data belonging to class i. The following formula can be used to calculate the Gini index.
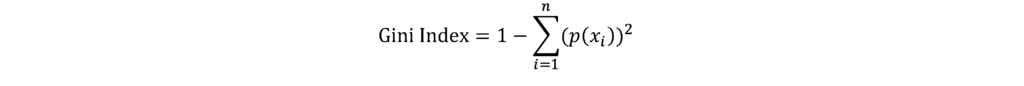
Algorithm Implementation with Code
Importing Libraries
For this example, we use scikit-learn, a popular machine learning library in python. Scikit-learn is a useful tool for creating datasets, training and testing algorithms, and much more. You must import all necessary libraries beforehand.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt #plots
%matplotlib inline
from sklearn.datasets import load_iris #dataset
from sklearn.model_selection import train_test_split #Splitting the data into testing and training data sets
from sklearn.preprocessing import StandardScaler #Standardize variables
from sklearn.tree import DecisionTreeClassifier #Decision Tree CLassifier Algorithm
from sklearn.metrics import classification_report,confusion_matrix,accuracy_score #Predictions and evaluations
Dataset
To create the dataset, we use load_iris. The iris dataset is a popular dataset used in machine learning. It contains information about 50 observations on four different variables: Petal Length, Petal Width, Sepal Length, and Sepal Width.
# load the iris dataset
iris = load_iris()
# store the feature matrix (X) and response vector (y)
X = iris.data
y = iris.target
Test Train Split
In this section, we split the dataset into training data and testing data. The objective is to train the algorithm to predict a value of y based on its associated X values. This allows us to test the performance of the algorithm against testing data by comparing the predicted values with the actual value.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30)
Feature Scaling
In this section, we use feature scaling, which is a preprocessing step that helps normalize the range of independent variables of varying magnitude. In the absence of feature scaling, algorithms weigh the influence of larger variables to be higher than smaller variables.
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
The next step is to create a Decision Tree object, fit it to the training data and generate predictions based on the test data.
dtree = DecisionTreeClassifier()
dtree.fit(X_train,y_train)
pred = dtree.predict(X_test)
Evaluation
Finally, we evaluate the predictions using a classification_report, which is used to measure the performance of a classification algorithm.
print(classification_report(y_test,pred))
print("Accuracy score: ", accuracy_score(y_test, pred))

The resulting accuracy value is 0.96. In business applications, you would use datasets generated from various business processes. However, the basic process of using the algorithm remains the same.
Tags: Supervised, Tree, Conditional Entropy, Gini Impurity, Recursive Learning, Overfitting, Pruning
AIPI3’s ML platform uses many innovative machine learning algorithms to create value for businesses. Our platform is driven by artificial intelligence & machine learning experts with extensive experience across a wide range of industries, specializations, and applications.
Get in touch with AIPI3 to discover how we can assist you!