ML Algorithm Explained: Naive Bayes
- By AIPI3 Machine Learning Team

Naïve Bayes is a supervised machine learning algorithm, which predicts the class of a given data point based on features of that point and the probability of belonging to that class. It assumes that features are completely independent of each other and they have no correlation between them. It is a probabilistic algorithm typically used for classification tasks. Naïve Bayes has many applications such as real-time predictions, text classification, spam detection, sentiment analysis, collaborative filtering, and much more.
Advantages:
- It is highly scalable and it can handle high-dimensional data.
- It is fast compared to other algorithms in many use cases especially when data sets are small.
Disadvantages:
- The speed of the algorithm can come at the expense of accuracy.
- The performance of more complicated algorithms is better with larger volumes of data.
In this blog post, we provide an overview of the Naïve Bayes algorithm with an example of algorithm implementation with code.
Basic Concepts
Assumptions
There are two key assumptions involved:
- All features are independent of each other.
- All features are of equal importance to the outcome.
Bayes Theorem
Naïve Bayes is based on the Bayes Theorem, which tells us that the probability of A occurring given that B occurs, P(A|B), can be calculated once we know the probability of B occurring given that A occurs, P(B|A), probability of A occurring, P(A), and the probability of B occurring, P(B).
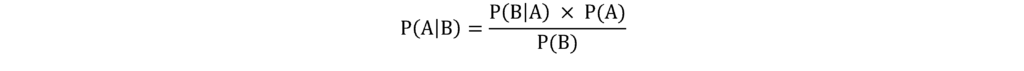
Naïve Bayes essentially uses X to predict y. If we apply the Bayes Theorem to the data we are interested in, the equation looks as follows:
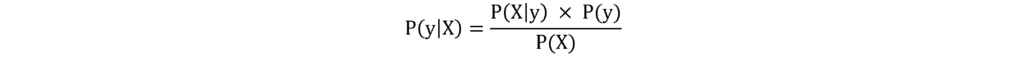
For a given data point, X may be connected to n different features:
The algorithm predicts the value of y using the following equation, where P(y) is called class probability and P(xi| y) is called conditional probability:
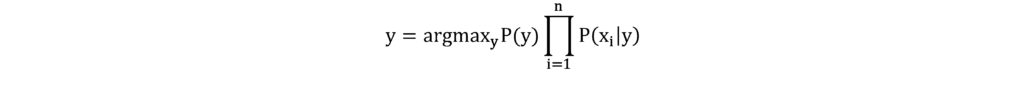
Algorithm Implementation with Code
Importing Libraries
For this example, we use scikit-learn, a popular machine learning library in python. Scikit-learn is a useful tool for creating datasets, training and testing algorithms, and much more. You must import all necessary libraries beforehand.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt #plots
%matplotlib inline
from sklearn.datasets import load_iris #dataset
from sklearn.model_selection import train_test_split #Splitting the data into testing and training data sets
from sklearn.naive_bayes import GaussianNB #Naive Bayes Classifier
from sklearn.metrics import classification_report,confusion_matrix #Predictions and evaluations
Dataset
To create the dataset, we use load_iris. The iris dataset is a popular dataset used in machine learning. It contains information about 50 observations on four different variables: Petal Length, Petal Width, Sepal Length, and Sepal Width.
# load the iris dataset
iris = load_iris()
# store the feature matrix (X) and response vector (y)
X = iris.data
y = iris.target
Test Train Split
In this section, we split the dataset into training data and testing data. The objective is to train the algorithm to predict a value of y based on its associated X values. This allows us to test the performance of the algorithm against testing data by comparing the predicted values with the actual value.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=1)
The next step is to create a Naïve Bayes Classifier object, fit it to the training data and generate predictions based on the test data. There are three main types of Naïve Bayes Classifiers: Gaussian, Multinomial, and Bernoulli. The choice of the classifier depends on the nature of your dataset. In this case, we select the Gaussian Naïve Bayes Classifier.
gnb = GaussianNB()
gnb.fit(X_train, y_train)
pred = gnb.predict(X_test)
Evaluation
Finally, we evaluate the predictions using a classification_report, which is used to measure the performance of a classification algorithm.
print(classification_report(y_test,pred))

The resulting accuracy value is 0.95 using a Gaussian Naïve Bayes Classifier. In business applications, you would use datasets generated from various business processes. However, the basic process of using the algorithm remains the same.
Tags: Supervised, Probabilistic, Parametric, Non-Linear, MLE, Bayes Rule
AIPI3’s ML platform uses many innovative machine learning algorithms to create value for businesses. Our platform is driven by artificial intelligence & machine learning experts with extensive experience across a wide range of industries, specializations, and applications.
Get in touch with AIPI3 to discover how we can assist you!