ML Algorithm Explained: Random Forests
- By AIPI3 Machine Learning Team

Random Forest is a supervised machine learning algorithm, which utilizes an ensemble of decision trees to predict values of given data points. Each decision tree predicts an output value and the output value with the highest number of occurrences becomes the output of the algorithm. It can be used for both classification and regression tasks. Random Forests has many applications such as fraud detection, credit scoring, medical diagnosis, and much more.
Advantages:
- It lowers the risk of overfitting by leveraging multiple decision trees
- It can handle different types of variables (continuous, discrete, etc.).
Disadvantages:
- It can require significant processing capability and time for training.
- It can be difficult to interpret compared to other algorithms.
In this blog post, we provide an overview of the Random Forest algorithm with an example of algorithm implementation with code.
Basic Concepts
Random Forests has three main parameters: node size, number of decision trees, and number of features. The algorithm uses n decision trees to generate a prediction. For a classification task, the algorithm identifies the class based on the class most frequently predicted by the decision trees. For regression tasks, the algorithm calculates a value based on the average of the value predicted by the decision trees.
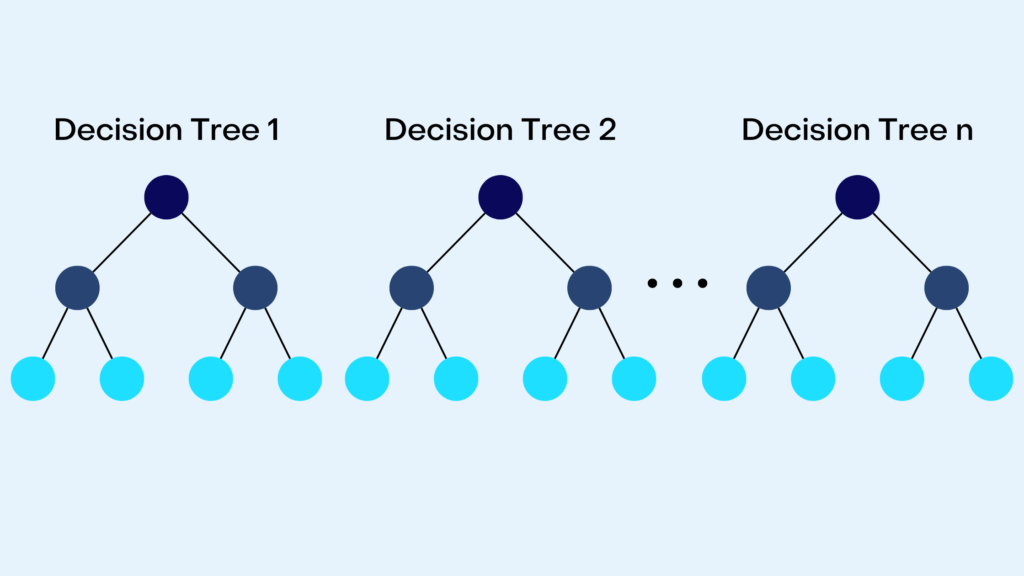
Algorithm Implementation with Code
Importing Libraries
For this example, we use scikit-learn, a popular machine learning library in python. Scikit-learn is a useful tool for creating datasets, training and testing algorithms, and much more. You must import all necessary libraries beforehand.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt #plots
%matplotlib inline
from sklearn.datasets import load_iris #dataset
from sklearn.model_selection import train_test_split #Splitting the data into testing and training data sets
from sklearn.ensemble import RandomForestClassifier #Random Forest Algorithm
from sklearn.metrics import classification_report,confusion_matrix,accuracy_score #Predictions and evaluations
Dataset
To create the dataset, we use load_iris. The iris dataset is a popular dataset used in machine learning. It contains information about 50 observations on four different variables: Petal Length, Petal Width, Sepal Length, and Sepal Width.
# load the iris dataset
iris = load_iris()
# store the feature matrix (X) and response vector (y)
X = iris.data
y = iris.target
Test Train Split
In this section, we split the dataset into training data and testing data. The objective is to train the algorithm to predict a value of y based on its associated X values. This allows us to test the performance of the algorithm against testing data by comparing the predicted values with the actual value.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30)
The next step is to create a Random Forest object, fit it to the training data and generate predictions based on the test data. Typically, the n_estimators is set to 100, which indicates that the algorithm will use 100 decision trees.
rfc = RandomForestClassifier(n_estimators=100)
rfc.fit(X_train, y_train)
pred = rfc.predict(X_test)
Evaluation
Finally, we evaluate the predictions using a classification_report, which is used to measure the performance of a classification algorithm.
print(classification_report(y_test,pred))
print("Accuracy score: ", accuracy_score(y_test, pred))
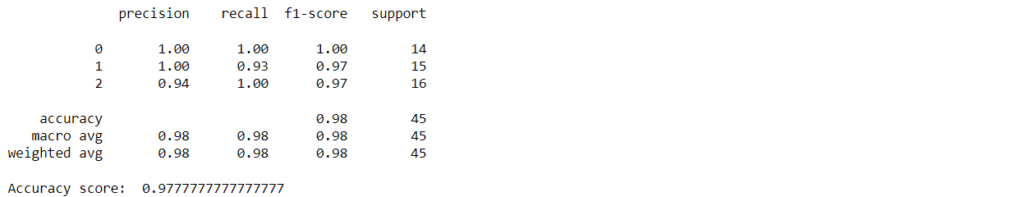
The resulting accuracy value is 0.98. In business applications, you would use datasets generated from various business processes. However, the basic process of using the algorithm remains the same.
Tags: Supervised, Tree, Conditional Entropy, Gini Impurity, Recursive Learning, Overfitting, Pruning
AIPI3’s ML platform uses many innovative machine learning algorithms to create value for businesses. Our platform is driven by artificial intelligence & machine learning experts with extensive experience across a wide range of industries, specializations, and applications.
Get in touch with AIPI3 to discover how we can assist you!