ML Algorithm Explained: K Nearest Neighbours
- By AIPI3 Machine Learning Team

K-Nearest Neighbors (KNN) is a supervised machine learning algorithm, which predicts the class of a given data point based on its distance to the nearest “k” number of points. While used for both regression and classification, it is primarily used in classification tasks. KNN has many applications such as content recommendation, image processing, risk assessment, pattern recognition, and much more.
Advantages:
- It is easy to implement due to its simplicity and ability to adapt to new data.
- It has fewer parameters to adjust compared to other algorithms.
Disadvantages:
- It is not scalable because performance drops as data volumes and complexity grow larger, which can increase computational costs.
- It does not work well when different classes of data points are too close together.
- It is very sensitive to noisy, mislabeled, and missing data and incorrect “k” value choices can lead to overfitting or underfitting.
In this blog post, we provide an overview of the KNN algorithm with an example of algorithm implementation with code.
Basic Concepts
KNN is a relatively simple algorithm with only two main parameters: a “k” value and a distance metric.
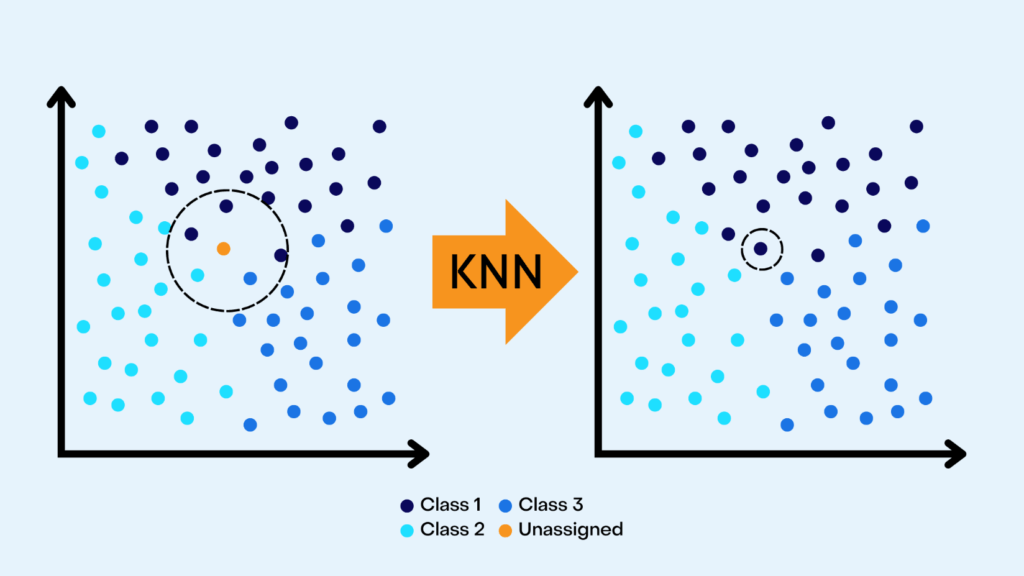
K-Value
The “k” value indicates the number of nearest data points that will be checked to determine the class of a given data point. For example, if “k” is set to 3, the algorithm checks the 3 closest points. The choice of “k” is dependent on the data under consideration but generally, it is recommended to have an odd “k” value to avoid ties.
Distance Metric
The distance metric is used to calculate the distance to the nearest point. While different decision measures can be chosen the most common is a Euclidean distance (Minkowski distance with p=2), which measures distance in a straight line between a given point and a neighboring point. The following formula is used to calculate this distance in a 2-dimensional space.
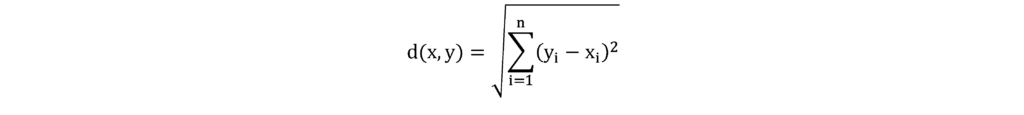
The distance between points is the sum of the square of the difference between the x and y coordinates of the points.
Algorithm Implementation with Code
Importing Libraries
For this example, we use scikit-learn, a popular machine learning library in python. Scikit-learn is a useful tool for creating datasets, training and testing algorithms, and much more. You must import all necessary libraries beforehand.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt #plots
%matplotlib inline
from sklearn.datasets import make_blobs #synthetic dataset
from sklearn.model_selection import train_test_split #Splitting the data into testing and training data sets
from sklearn.neighbors import KNeighborsClassifier #KNN Algorithm
from sklearn.metrics import classification_report,confusion_matrix #Predictions and evaluations
Dataset
To create a synthetic dataset, we use make_blobs. The code below created a data set with 500 samples divided into 4 classes and 2 features.
#create synthetic dataset
X, y = make_blobs(n_samples = 500, n_features = 2, centers = 4,
cluster_std = 1.5, random_state = 2)
#scatter plot of dataset
plt.figure(figsize = (10,6))
plt.scatter(X[:,0], X[:,1], c=y, marker= 'o', s=50)
plt.show()
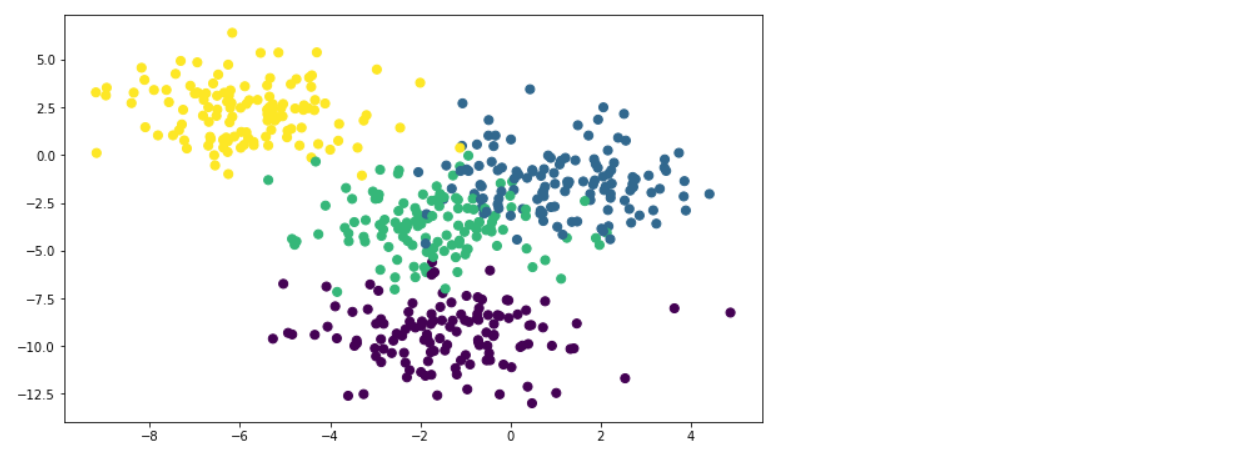
Test Train Split
In this section, we split the dataset into training data and testing data. The objective is to train the algorithm to predict a value of y based on its associated X values. This allows us to test the performance of the algorithm against testing data by comparing the predicted values with the actual value.
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0)
The next step is to create a KNN Classifier object, fit it to the training data and generate predictions based on the test data. Typically, the initial value of k is 1.
knn = KNeighborsClassifier(n_neighbors=1) #choosing k=1
knn.fit(X_train,y_train)
pred = knn.predict(X_test)
Evaluation
Finally, we evaluate the predictions using a classification_report, which is used to measure the performance of a classification algorithm.
print(classification_report(y_test,pred))
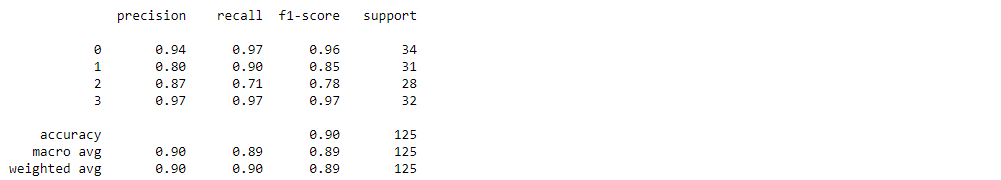
The resulting accuracy value is 0.90 with k=1. For a KNN algorithm, the choice of K value is critical, therefore, we further check the algorithm performance against various K values by looking at the error rate and accuracy.
Choosing a K Value
The code below calculates and compares the algorithm’s error rate against a range of K values and visualizes the results in a plot:
error_rate = []
# Will take some time
for i in range(1,40):
knn = KNeighborsClassifier(n_neighbors=i)
knn.fit(X_train,y_train)
pred_i = knn.predict(X_test)
error_rate.append(np.mean(pred_i != y_test))
plt.figure(figsize=(10,6))
plt.plot(range(1,40),error_rate,color='blue', linestyle='dashed', marker='o',
markerfacecolor='red', markersize=10)
plt.title('Error Rate vs. K Value')
plt.xlabel('K')
plt.ylabel('Error Rate')
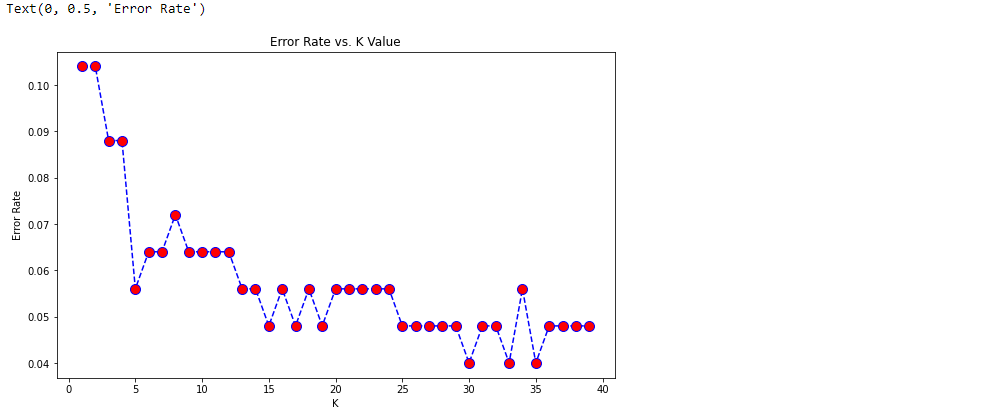
Around K=30 the error rate is at its lowest. To confirm if this is a good k-value we can look at the accuracy. The code below calculates and compares the algorithm’s accuracy against the same range of K values and visualizes the results in a plot.
acc = []
# Will take some time
from sklearn import metrics
for i in range(1,40):
neigh = KNeighborsClassifier(n_neighbors = i).fit(X_train,y_train)
yhat = neigh.predict(X_test)
acc.append(metrics.accuracy_score(y_test, yhat))
plt.figure(figsize=(10,6))
plt.plot(range(1,40),acc,color = 'blue',linestyle='dashed',
marker='o',markerfacecolor='red', markersize=10)
plt.title('Accuracy vs. K Value')
plt.xlabel('K')
plt.ylabel('Accuracy')
print("Maximum accuracy:-",max(acc),"at K =",acc.index(max(acc)))
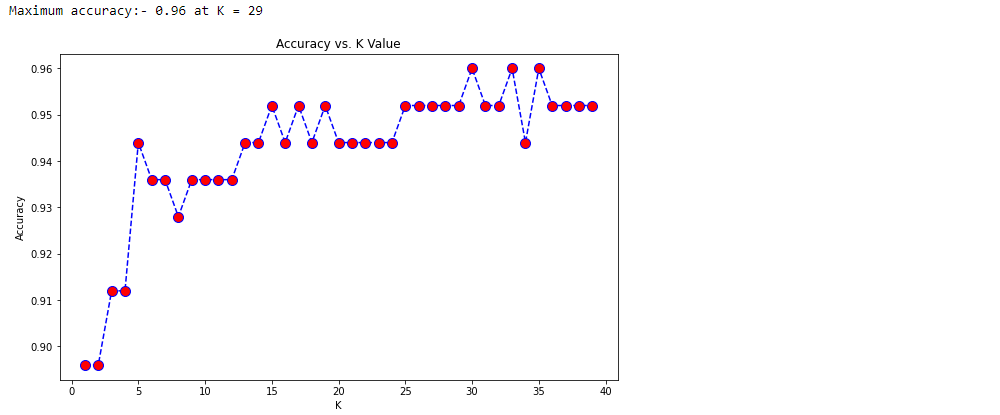
We have confirmed that accuracy is the highest at K=30. Therefore, we can retrain the algorithm and check the classification report with this new k value.
# NOW WITH K=30
knn = KNeighborsClassifier(n_neighbors=30)
knn.fit(X_train,y_train)
pred = knn.predict(X_test)
print('WITH K=30')
print(classification_report(y_test,pred))

The resulting accuracy value is 0.96 with k=30, which confirms that the algorithm performance has been improved by choosing a better K value. In business applications, you would use datasets generated from various business processes. However, the basic process of using the algorithm remains the same.
Tags: Supervised, Non-Parametric, Non-Linear, Kernel Trick
AIPI3’s ML platform uses many innovative machine learning algorithms to create value for businesses. Our platform is driven by artificial intelligence & machine learning experts with extensive experience across a wide range of industries, specializations, and applications.
Get in touch with AIPI3 to discover how we can assist you!